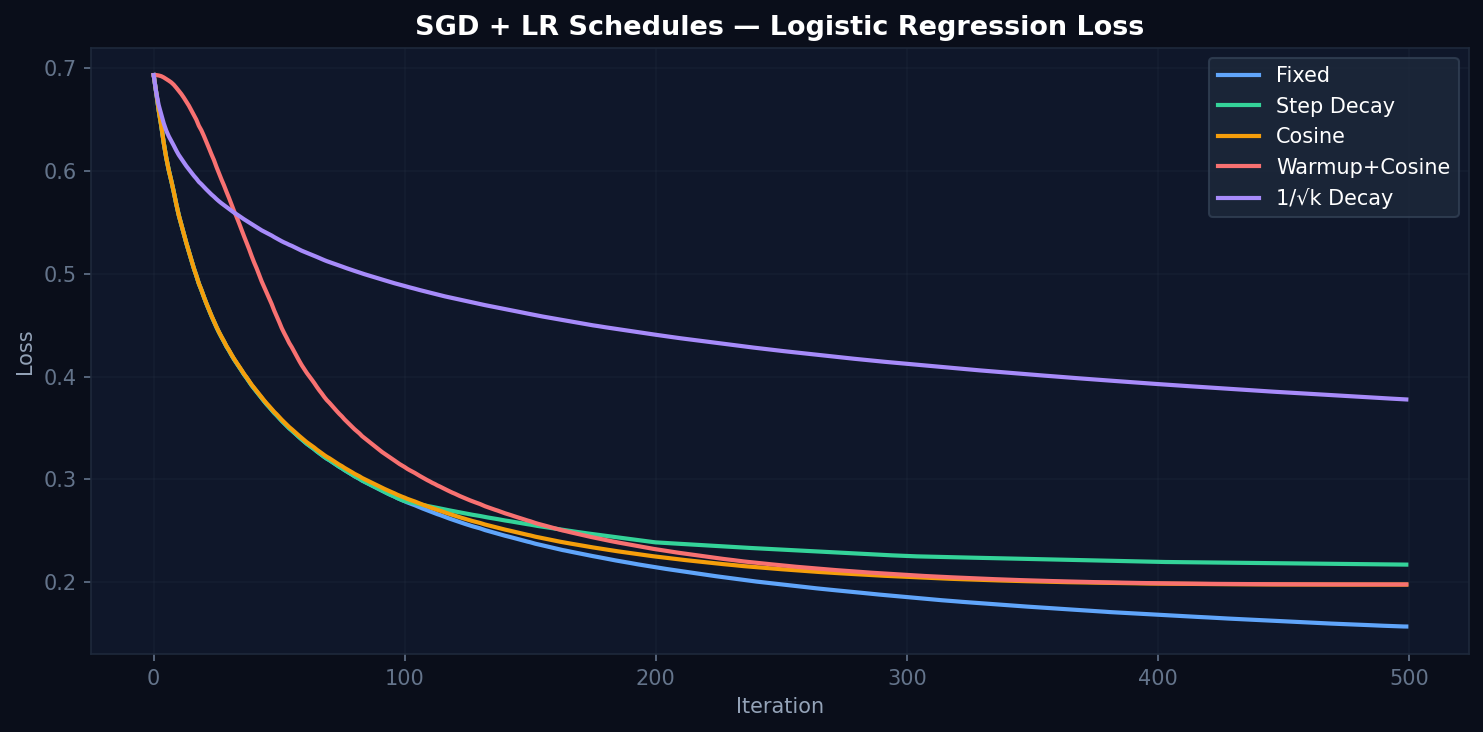
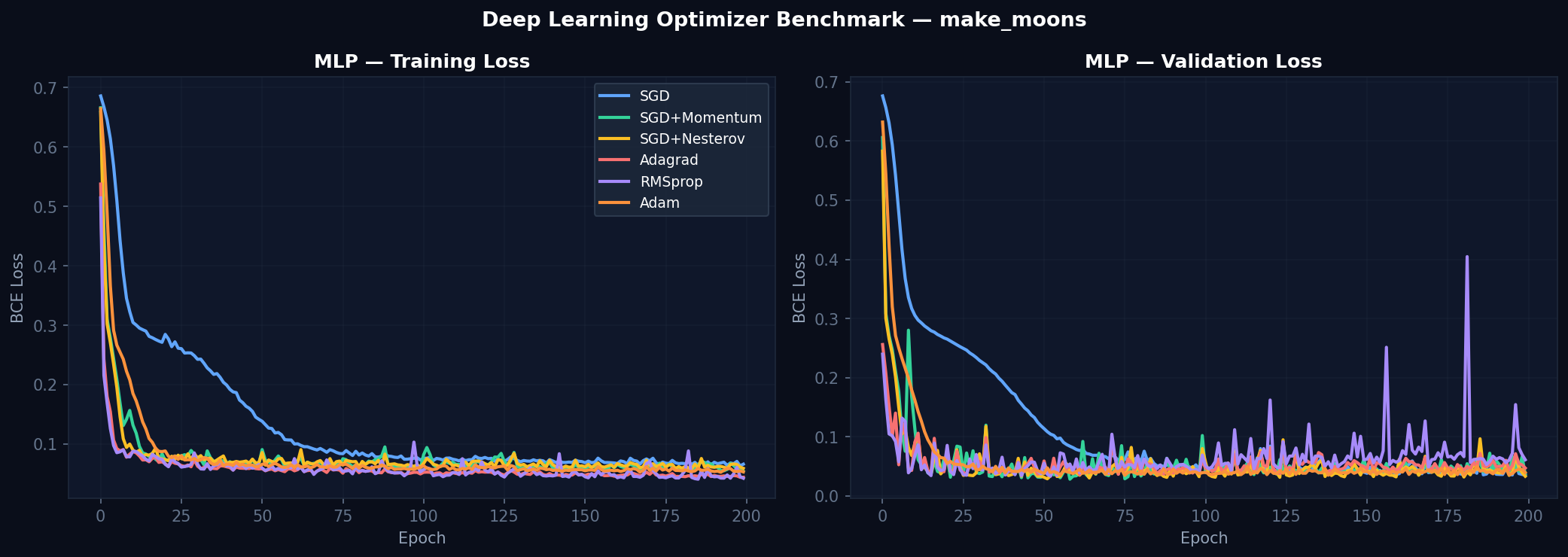
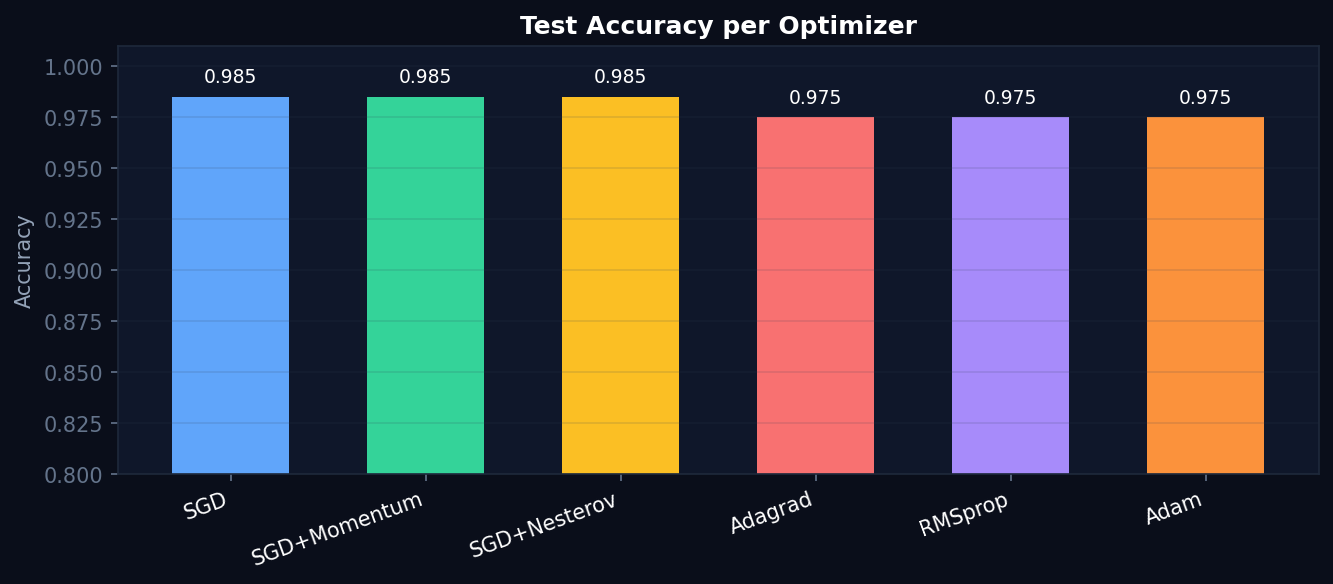
Convergence Results
Experiment Outputs
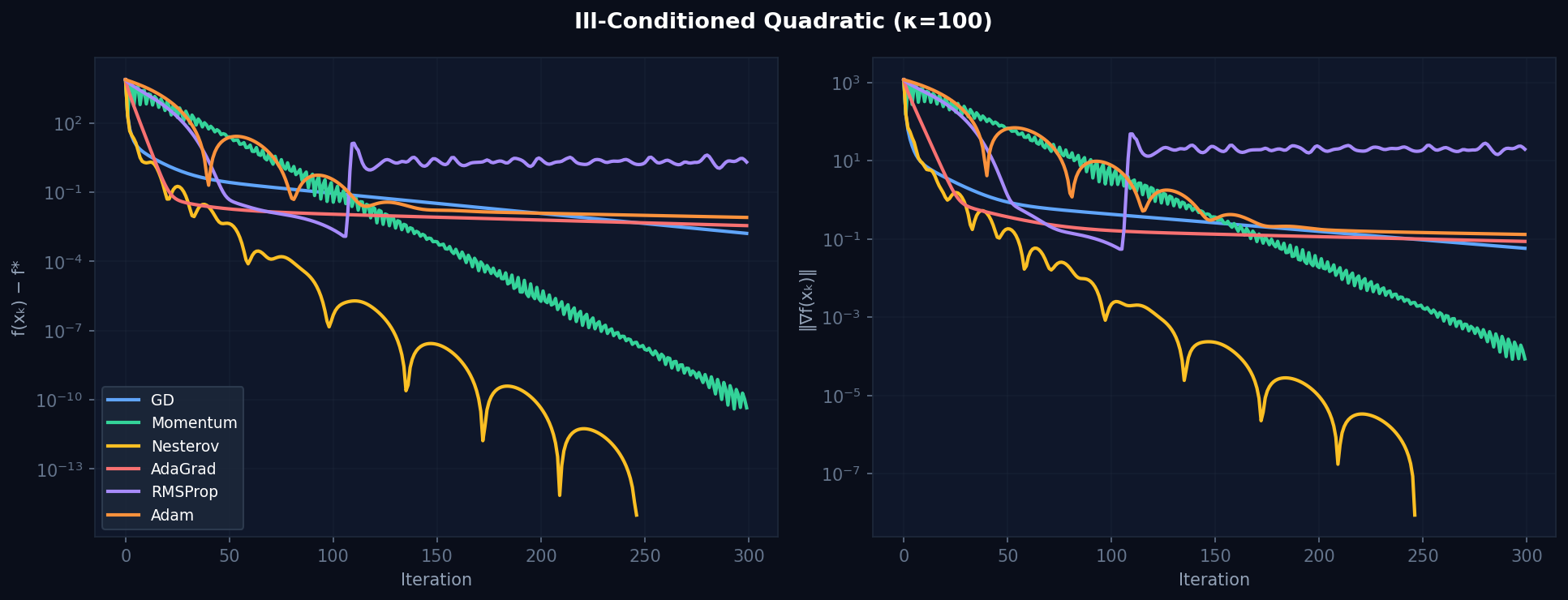
Figure 1. Ill-conditioned quadratic (κ=100) — suboptimality (left) and gradient norm (right). Adam and Nesterov converge in ~50–80 iterations; GD takes 300+ and still lags behind.
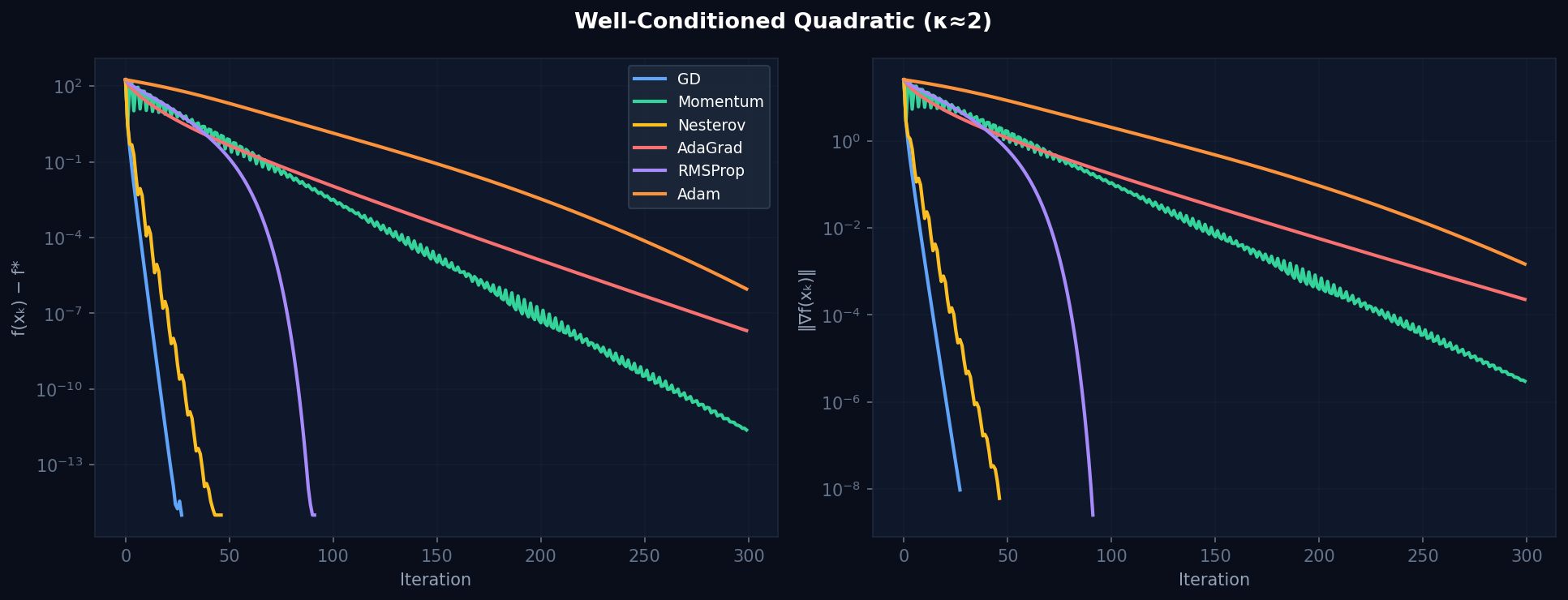
Figure 2. Well-conditioned quadratic (κ=2). All optimizers converge — differences are small. Nesterov and Adam reach machine precision earliest.
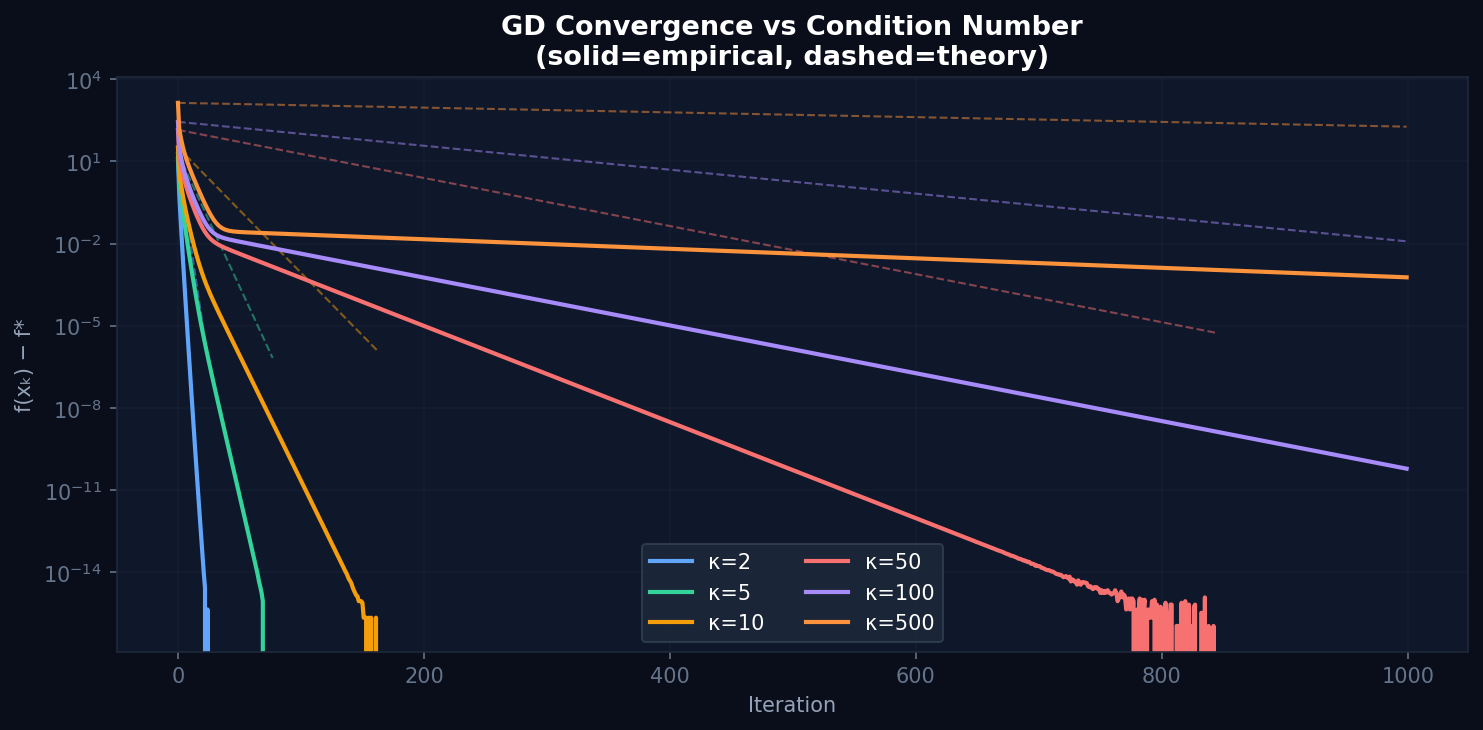
Figure 3. GD convergence vs condition number κ ∈ {2, 5, 10, 50, 100, 500}. Solid lines are empirical; dashed lines are the theoretical bound ((κ−1)/(κ+1))^k. κ=500 does not converge in 1000 iterations.
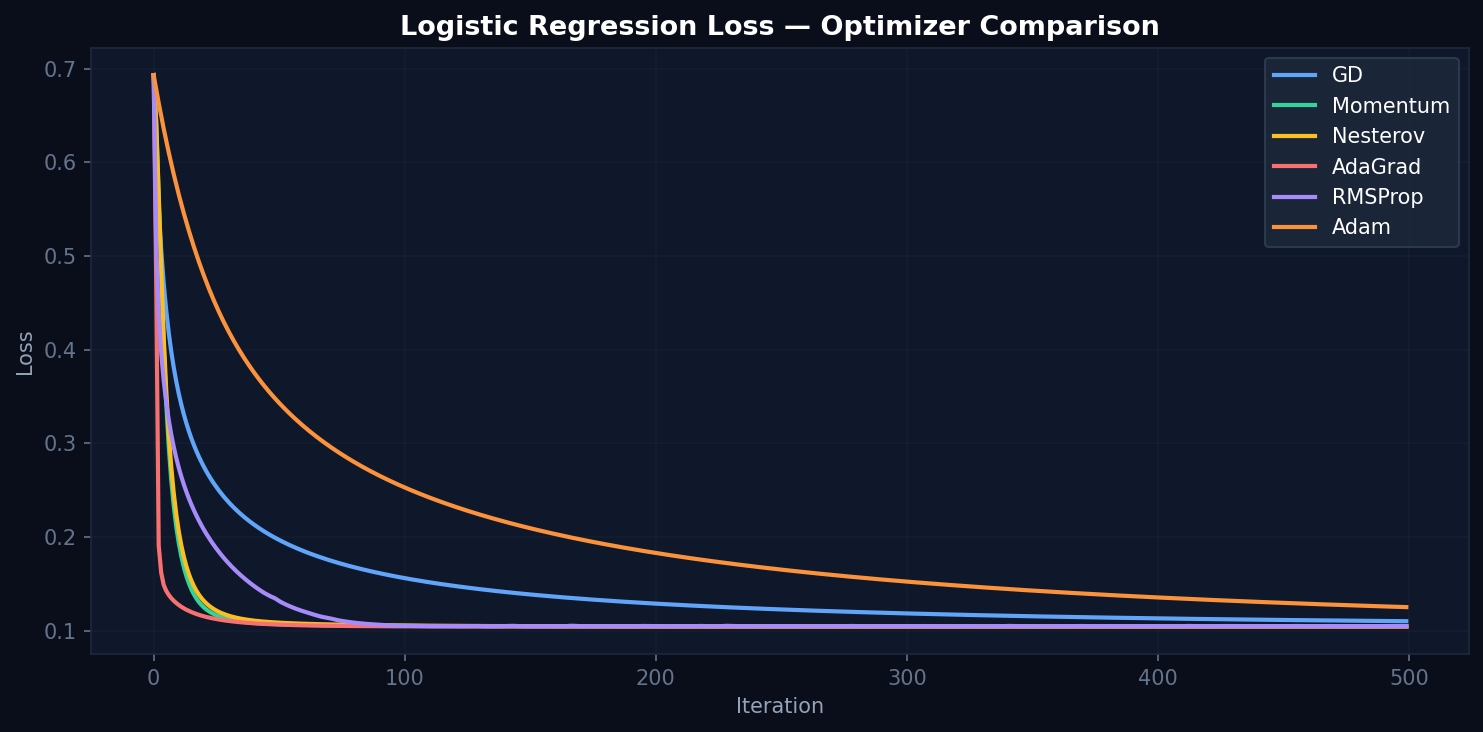
Figure 4. Logistic regression loss. Momentum, Nesterov, RMSProp reach ~0.10 within 100 iterations. Adam converges slowly here.
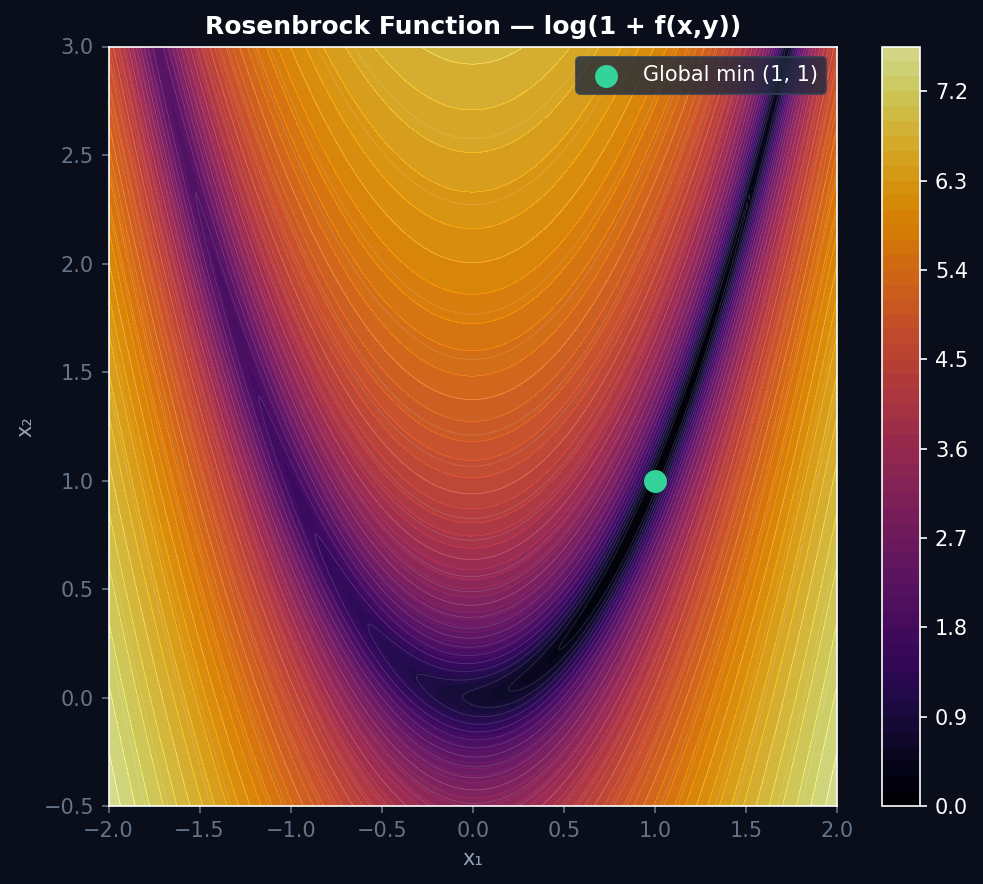
Figure 5. Rosenbrock landscape (log scale). The narrow banana-shaped valley curving toward the global min at (1, 1).